
Page 26 - 臺大管理論叢第33卷第1期
P. 26
An Integrated Data-Driven Methodology for Auditor Performance Appraisals and Auditor Assignment
Optimization
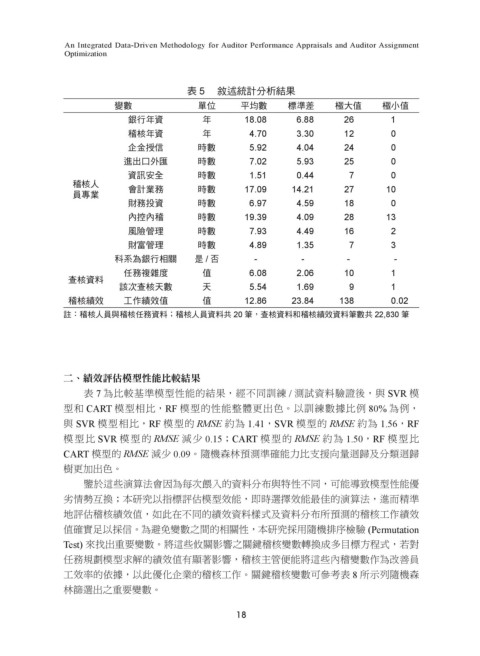
表 5 敘述統計分析結果
變數 單位 平均數 標準差 極大值 極小值
銀行年資 年 18.08 6.88 26 1
稽核年資 年 4.70 3.30 12 0
企金授信 時數 5.92 4.04 24 0
進出口外匯 時數 7.02 5.93 25 0
資訊安全 時數 1.51 0.44 7 0
稽核人 會計業務 時數 17.09 14.21 27 10
員專業
財務投資 時數 6.97 4.59 18 0
內控內稽 時數 19.39 4.09 28 13
風險管理 時數 7.93 4.49 16 2
財富管理 時數 4.89 1.35 7 3
科系為銀行相關 是 / 否 - - - -
任務複雜度 值 6.08 2.06 10 1
查核資料
該次查核天數 天 5.54 1.69 9 1
稽核績效 工作績效值 值 12.86 23.84 138 0.02
註:稽核人員與稽核任務資料;稽核人員資料共 20 筆,查核資料和稽核績效資料筆數共 22,830 筆
二、績效評估模型性能比較結果
表 7 為比較基準模型性能的結果,經不同訓練 / 測試資料驗證後,與 SVR 模
型和 CART 模型相比,RF 模型的性能整體更出色。以訓練數據比例 80% 為例,
與 SVR 模型相比,RF 模型的 RMSE 約為 1.41,SVR 模型的 RMSE 約為 1.56,RF
模型比 SVR 模型的 RMSE 減少 0.15;CART 模型的 RMSE 約為 1.50,RF 模型比
CART 模型的 RMSE 減少 0.09。隨機森林預測準確能力比支援向量迴歸及分類迴歸
樹更加出色。
鑒於這些演算法會因為每次餵入的資料分布與特性不同,可能導致模型性能優
劣情勢互換;本研究以指標評估模型效能,即時選擇效能最佳的演算法,進而精準
地評估稽核績效值,如此在不同的績效資料樣式及資料分布所預測的稽核工作績效
值確實足以採信。為避免變數之間的相關性,本研究採用隨機排序檢驗 (Permutation
Test) 來找出重要變數。將這些攸關影響之關鍵稽核變數轉換成多目標方程式,若對
任務規劃模型求解的績效值有顯著影響,稽核主管便能將這些內稽變數作為改善員
工效率的依據,以此優化企業的稽核工作。關鍵稽核變數可參考表 8 所示列隨機森
林篩選出之重要變數。
18